If, as you read this post, it feels like you have read it or a close variant before, it is because you have. Each year, ahead of teaching my classes at NYU's Stern School of Business in the spring, I invite readers to accompany me on my journey, and this year is no different. Starting in late January 2023, I will be back in the classroom, teaching valuation and corporate finance to the MBAs and valuation to the undergraduates, and these classes will continue through May 2023. If you are curious about the content of these classes, and may want to partake, I will use this post to lay out my teaching philosophy, to describe the classes that I teach and provide options that you may be able to use to take them.
Teaching Philosophy
I have heard the old saying that "those who can do, and those who cannot teach", and I won't get defensive in response, because it may be true. I would like to believe that I am capable of both doing and teaching valuation and corporate finance, but I will leave that judgment for you to make, since my valuations and corporate finance assessments are in the public domain (on my blog and in my lecture notes). If your query is why I would continue to teach rather than seek out more lucrative careers in investing or banking, my answer is a simple one. I love teaching and if you follow my classes, I hope it shows, and my teaching philosophy can be summarized in six precepts:
Preparation is key: Paraphrasing Edison, teaching is 90% perspiration and 10% inspiration. If you are prepared for your class, you are well on your way to being a good teacher.
Respect your students: I believe that anyone who sits on my classroom is as capable as I am, though perhaps not as experienced, and is passionate about learning.
Be fair: I don't believe that students dislike or punish tough teachers, but I do believe that they dislike and punish teachers who are unfair, either in the way they test students or in the way they grade them. I know that I will make mistakes, but as long as I keep an open door and correct my mistakes, I think that students will cut me some slack.
Have empathy: It has been a long time since I was a student in a classroom, but I try to keep my memory fresh by remembering the things I disliked in my classes and trying not to repeat them.
Teaching is not just in the classroom: My impact on students does not come just from what what I do in the classroom. It is affected just as much but what I do outside the classroom, in my office hours and in my interactions (online and in person) with my students.
Have fun: If you look at the joy that young children show when they learn something new, it is obvious that human beings enjoy learning (though our education systems are often designed to stamp out that joy). I want my classes to be meaningful, impactful and profound, but I also want them to be fun. For that to happen, I have to have fun teaching and I will!
Older, though not wiser, as I start my 37th year teaching at NYU, I am looking forward to class just as much as I did the very first year that taught, as a visiting lecturer at the University of California at Berkeley in the fall of 1984.
Course Offerings
I am a dabbler, someone who knows a little bit about a whole host of subjects, without being close to an expert on any one of them. In a world where specialization is the norm, this does put me at a bit of a disadvantage, since there are many who know a great deal more about almost any topic that I choose to talk about, but I do think that it gives me a big-picture perspective that helps me find answers. As you will see in this section, I teach a range of courses, and I hope that my teaching of each course is informed by thinking about and teaching of the other courses.
1. Pre-game Prep
If there is a lesson be learnt from the last few years of market mayhem, it is that far too many investors, professional as well as retail, seem to have lost their moorings (or never had them in the first place), when it comes to the basics of accounting, finance and statistics. In the last few years, I have created my own versions of each of these disciplines, reflecting the tools and skills that I draw upon in my valuation and corporate finance classes.
a. Accounting
Much of the raw data that you use in corporate finance and valuation comes from accounting statements, and if you do not understand the difference between operating and net income, you are fatally handicapped. If your accounting basics are strong, you can move right along, but if they are shaky, I have an abbreviated online accounting class, with twelve sessions that around built around using the financial statements (income statement, balance sheet and statement of cash flows) to assess a firm’s financial standing, as a prelude to analyzing or valuing it.
Just as a note of warning, this is my quirky version of accounting, and I don’t follow the accounting script in this class. I challenge what I see as indefensible practices in accounting, including the expensing of R&D (a capital expense) and inconsistencies in accounting ratios.
b. Foundations of Finance
I also have a 12-session foundations of finance class, where I introduce two structures that I draw on all through my classes - the financial balance sheet (as opposed to an accounting balance sheet) and a corporate life cycle. I provide an introduction to cash flows and risk, and how they play out in the time value of money, and the basics of valuing contractual cash flows (bonds), residual cash flows (equity) and contingent cash flows (options). Finally, I carve out simple (even simplistic) sessions on inflation, interest rates and exchange rate, three macro variables that we are exposed to in almost all financial analysis and valuations.
Again, if your finance basics are solid, and you understand the link between expected inflation, interest rates and exchange rates, you can skip this class.
c. Statistics
The most recent addition to my class list is one on statistics, and it was motivated by the wanton misuse and misunderstanding of data that I see not only in investing, but in the rest of life. It is ironic, and perhaps telling, that our understanding of statistics seems to have hit rock bottom in the age of big data. In this class, I start by looking at data collection and data descriptives, before moving on to distributions and data relationships (correlations, covariances and regressions) and closing with probabilities and probabilistic tools.
If you find yourself inundated by data in financial analysis, I hope this class helps you convert data to information, and data that matters from data that distracts.
2. Corporate Finance
If the introductory classes in accounting, finance and foundations don’t exhaust you, you are welcome to my corporate finance class, which covers the first principles that govern how to run a business. The class starts with a question of what the end game should be for a business (profitability, value, social good?), and uses that endgame to cast light on the investing, financing and dividend decisions that all businesses, small or large, private or public, have to make.
This is a big picture class, designed not for bankers and consultants, but for a much broader audience of business owners, entrepreneurs and investors. If you have struggled with why debt helps some companies and hinders others, or how stock buybacks affect shareholders, I hope that you will give this class a try. It is also a relentlessly applied class, where every concept that is introduced in class is applied on companies that range the spectrum: a multinational entertainment company facing leadership challenges (Disney), a family-group automobile company (Tata Motors), a bank with a storied past and a troubled present (Deutsche Bank), an emerging-market mining company (Vale), a Chinese search engine (Baidu) and a small privately owned bookstore in New York City.
Along the way, I will use the corporate life cycle to illustrate how the corporate finance focus of a business changes as it ages, from investing (in young companies) to financing (in mature businesses) to dividends (in declining businesses):
It will help make my case that companies that act in age-inappropriate ways (a young company that borrows large amounts, a mature company that relentlessly chases growth or a declining firm looking for reincarnation) destroy value, while making their bankers and consultants wealthy.
3. Valuation
In 1986, when I taught the first semester-long valuation class at NYU, I was told that there was not enough material for a class that long. I persevered, and thirty seven years later, I think I can say, with some confidence, that I have enough material to fill a semester-long class. This is a class in search of pragmatic solutions, not purity or theory, and it is my intent is to value assets, companies and investments, not just talk about valuing them.
I have argued that valuation books and courses do a disservice by focusing all their attention on money-making publicly-traded companies, with long histories and mostly in developed markets, leaving readers and students with the false impression that you cannot value young companies., firms in emerging markets or private businesses. I claim, perhaps boastfully, in my first session of this class that this is a class about valuing or pricing just about anything, including private business, assets, collectibles and even cryptos.
I use the corporate life cycle to talk about how the challenges in valuing and pricing companies shift as you move from start-ups to companies in decline:
As with the corporate finance class, I cast my net wide, when it comes to my audience, and while the class will help prepare you for a valuation career, as an equity research analyst or appraiser, the class is designed for anyone who has ever struggled with understanding valuation and market pricing. This may surprise you, but we spend a significant amount of time in this class talking about telling business stories that pass the “fairy tale” test and tying stories to valuation inputs, and almost no time opening and closing spreadsheets. So, whether you are a number cruncher or story teller, I think you will find something to take away from the class.
4. Investment Philosophy
The last class that I teach, albeit only online, is one on investment philosophies, and it was born from two observing two investing realities.
The first is that notwithstanding the hundreds of books on how to beat the market and the thousands of cannot-miss trading strategies that exist on paper, there are only a handful of investors and traders who have consistently beaten the market over long periods.
The second is that these consistent winners have very little in common, in terms of market beliefs and strategies, with value investors, market timers and traders in the mix.
My reading of these two realities is that there is no one best investment philosophy, that works for everyone, but there is one best philosophy for you, given your personal make up and investable capital. Consequently, this class lays out a menu of investment philosophies, from short-term (day) trading to long-term value investing, from passive to active to activist investing and from stock picking to market timing, with the intent of letting you find the investment philosophy that is right for you.
As with my corporate finance and valuation classes, I argue that your choice of investment philosophy will determine where in the corporate life cycle, you will find your investments.
If you believe that markets make mistakes in valuing assets-in-place, i.e., you are a value investor, your portfolio will be composed of mature companies. In contrast, if your view is that markets make mistakes in valuing growth assets, i.e., you are a growth investor, your investments will be primarily from growth companies.
Choices, choices, choices...
You have lives to live, work to do and families to be with, and it is unrealistic and arrogant of me to expect you to spend a large portion of your time, taking my classes. I will settle for what I can get, and offer my classes in multiple formats, tailored to different time constraints and diverse tastes.
Formats
There are three formats in which I offer my classes, though not all of the classes are available in every format.
Regular classes (Free): My corporate finance and valuation classes are taught, as semester-long classes, meeting twice a week for 80-minute sessions. While you need to be registered in the classes, as Stern students, to be able to sit in the classrooms, the sessions will be recorded and accessible by the end of the class day. You can take the class this upcoming semester, when the classes start late January 2023 and continue through May 2023, or watch the archived versions from spring 2022.
Note that the MBA and undergraduate valuation classes are identical in content, and you can take one or the other. If you decide to take the class, you will have access to everything that my students will have, from the slides that I use in the class, to the tests and exams that I give, with solutions that you can use to grade yourself, to the emails that I send my students on an almost daily basis. You can even do the projects (a corporate financial analysis in the corporate finance class or valuing & pricing a company in the valuation class) that are required for the classes. The downside is that this is the most time consuming of the choices, and much as I try, my 80-minute sessions cannot compete with The White Lotus for entertainment value.
Online classes (Free): If you find yourself unable to invest the time needed to take my regular classes or find the long sessions unwatchable (I don't blame you..), I have online versions of these classes that compress the 80-minute sessions into 12-15 minutes. It is a testimonial to the bloat in MBA programs that I can do this without compromising much on content, and these sessions also come with supporting material.
One downside is that many of these online sessions were recorded a few years ago, and you may find no mention of valuation challenges of today, from how the COVID crisis upended value and the steep fall in FANGAM stocks this year. Another is that even if you watch every video, take every post-class test and feel that you have mastered the material, I cannot offer you any official affirmation or certification for taking the class, but on the flip side, the courses are free!
Certificate classes (Not free): If certification is what you seek, New York University offers my three main courses as certificate classes. The content is similar to that in my online classes, but the videos are more polished, the classes follow a calendar and I do have an online meetup on zoom every two weeks:
In keeping with the adage that there is no free lunch, you will have to pay for the certification privilege, and if the price gives you sticker shock, please remember that I have no role in that pricing decision and offer a free version, with the same content.
Sequencing
If you are interested but are unclear about where to start, I am reproducing a flow chart I created last year to guide you through my classes.
As you can see, the sequencing of classes depends upon your background, as well as your interests. Specifically, if you are mostly interested in running or helping to run a business, the only class that you may need is a corporate finance class, supplemented by, if necessary, one or more of the three prep classes (accounting, basic finance and statistics). If your interests lie in learning the craft of valuation, perhaps because your job requires it or because you are curious, my recommendation is that you take both the corporate finance and valuation classes. If investing is what rings your bell, the valuation class twinned with an investment philosophy class should get you to wherever you want to go.
Supporting Cast
Watching a video of a class is just the first step in learning. To help, I try to provide as much supporting material as I can. As you look down the list, please do not be intimidated by its length, since you may find a use for only a portion of what I offer:
Lecture Notes: The only material that I require for the students in my class are the lecture note slides that I use in the class, and the only reason I require it is to reduce the amount of note-taking during class. The slides are available as full packets for my regular classes, on the webpages for the classes (see above), but they are also available with each session as links. As you review these slides, you will note that I break every rule in creating slides, cramming in way too much information on each slide. I am sorry for doing so, but my intent is to allow these slides to be the equivalent of class notes.
Post-class test: Every session of each class comes with a post-class test. These tests take about 15 minutes to do, and are a review of the material covered during the class. If you have the time, it is worth taking these tests to reaffirm what you are learning.
Data: The data that I reference during the class are available in their most updated formats on my webpage, under current data, with the next update due at the start of 2023.
Spreadsheets: I almost never open an excel spreadsheet during my classes and spend little time on financial modeling, but I do use my limited Excel skills, when valuing companies and doing corporate financial analysis. To save you the trouble of building spreadsheets from scratch, I leave my spreadsheets online for you to access, adapt and change.
Tools videos: As I noted earlier, my classes are applied, and to provide guidance on applying what I teach to real life, I have YouTube videos on almost every application, from how to read an annual report all the way to a full company valuation.
Blog Posts: If you find the material in my classes of interest, you can read my blog on Google Blogger and Substack. I don't post often, but when I do, my posts tend to focus on valuation, corporate finance and investment philosophy topics.
Books: I have books on each of the topics that I teach, but you do not need any of them to get through these classes. Some of these books are obscenely over-priced, and I don't require them for any of my classes.
Starting on an online class is easy, but finishing the class is difficult. One obvious reason is time and commitment, and I will have to leave it to you to figure that one out, but another is that a class is more than a collection of lectures. There is a peer-group component to learning that includes class discussions and group interactions that is often absent in big online classes, leaving you not only with unanswered questions, but also missing the critical part of learning that comes from explaining concepts to, and bouncing ideas off, others in the class.
I do not have the bandwidth to be able to provide direct support to everyone taking my classes, but a few months ago, I was approached by Sebastian Marambio, who has set up a neat site called We are six, allowing people to set up groups to work with, for online classes, with apps available for Android and iOS. Once you register on the site, you can enter the class code for the class that you then proceed to create a group with others with similar time frames and compatible time zones for taking the class. Sebastian has been kind enough to set up free versions for my online classes and the links to them are below:
Class
Course Code (for We are Six groups)
Corporate Finance (Online)
ADCorp
Valuation (Online)
ADValu
Investment Philosophies (Online)
ADPhil
If you are taking the regular versions of my corporate finance and valuation classes, please hold off, and we may create versions for those classes. I am looking forward to seeing how this experiment unfolds, since it will fill a gap in all online classes for organized group interactions.
In my first two posts on Facebook, I noted that its most recent earnings report, and the market reaction to it, offers an opportunity for us to talk about bigger issues. I started by examining corporate governance, or its absence, and argued that some of the frustration that investors in Facebook feel about their views being ignored can be traced to a choice that they made early to give up the power to change management, by acquiescing to dual class shares. Facebook, I argued, is a corporate autocracy, with Mark Zuckerberg at its helm. In the second post, I pointed to inconsistencies in how accountants classify operating, capital and financing expenses, and the consequences for reported accounting numbers. Some of the bad news in Facebook's earnings report, especially relating to lower profitability, reflected accounting mis-categorization of R&D and expenses at Reality Labs (Facebook's Metaverse entree) as operating, rather than capital expenses. In fact, I concluded the post by arguing that investors in Facebook were pricing in their belief that the billions of dollars the company had invested in the Metaverse would be wasted, and argued that Facebook faced some of the blame, for not telling a compelling story to back the investment. In this post, I want to focus on that point, starting with a discussion of why stories matter to investors and traders and the story that propelled the company to a trillion-dollar market capitalization not that long ago. I will close with a look at why business stories can break, change and shift, focusing in particular on the forces pushing Facebook to expand or perhaps even change its story, and whether the odds favor them in that endeavor.
Narrative and Value
As someone who has spent the last four decades talking, teaching and doing valuation that we have lost our way in valuation. Even as data has become more accessible and our tools have become more powerful, it is my belief that the quality of valuations has degraded over time. One reason is that valuation, at least as practiced, has become financial modeling, where Excel ninjas pull numbers from financial statements, put them into spreadsheets and extrapolate based upon past trends. Along the way, we have lost a key component of valuation, which is that every valuation tells a business story, and understanding what the story is and its weakest links is key to good valuation,
The Connection
In the first session of my valuation class, I pose a question, "What comes more naturally to you, telling a story or working with numbers?", and I very quickly add that there is no right answer that I am looking for. That is because the answer will vary across people, with some exhibiting a more natural tendency towards story-telling and others towards working with numbers. In my valuation classes, the selection bias that leads people to come back to business school, and then to pick the valuation class as an elective, also results in the majority picking the "numbers" side, though I am glad to say that I have enough history majors and literature buffs to create a sizable "story" contingent. In the immediate aftermath, I then put forth what I believe is one of the biggest hidden secrets in valuation, which is that a good valuation is not just numbers on a spreadsheet, which is the number-crunching vision, or a big business story, which is the story-tellers' variant, but a bridge between stories and numbers:
To explain what I mean by "a bridge", in a good valuation, every number you have in your valuation, from growth to margins to risk measures, should be backed up by a story about that number, and every story you tell about a company, including its great management, brand name or technological edge, has be reflected in a number in your valuation. If making this connection comes naturally to you, you are lucky and definitely the exception, because it is hard work for the rest of us. As someone who is more naturally drawn to numbers, I came to the recognition of the need for stories late to the game, and I had not only to teach myself how to tell stories but also create a process where I stayed disciplined about incorporating them into valuations. In case you are interested, I did write a book on the process that I use to convert stories to numbers, but if you are budget-constrained, many of the ideas in the book are captured in posts that I have done over time on valuation.
Stories + Numbers: The Symbiosis
The challenge in valuation, and it has only become worse in time, is that the divide between story tellers and number crunchers has only become wider over time, and has reached a point where each side not only does not understand the other, but also views it with contempt. Venture capitalist, raised on a diet of big stories and total addressable markets has little in common with bankers, trained to think in terms of EV to EBITDA multiples and accounting ROIC, and when put in a room together, it should come as no surprise that they find each other's language indecipherable. At the risk of being shunned by both groups, I will argue int his section that each side will benefit, from learning to understand and use the tools of the other side.
1. Why stories matter in a numbers world
If you are a numbers valuation, you start with some advantages. Not only will you find financial statements easier to disentangle, but you will also be able to develop a framework for converting these numbers to forecasts fairly easily. In other words, you will have no trouble creating something that looks like a legitimate valuation, with numbers details and an end value, even if that value is nonsensical. With a just-the-numbers valuation, there are four dangers that you face:
Play with numbers: When a valuation is all about the numbers, it is easy to start playing with the numbers, unconstrained by any business sense, and change the value. It is not uncommon to see analysts, when they estimate a value that they think is "too low", to increase the revenue growth rate for a company, holding all else constant, and increase the value to what they would "like it to be".
False precision: Number crunchers love precision, and the pathways they adopt to get to more precise valuations are often counter-productive, in terms of delivering more accurate valuations. From estimating the cost of capital to the fourth decimal point to forecasting all three accounting statements (income statements, balance sheet and statement of cashflows), in excruciating detail, for the next 20 years, analysts lose the forest for the trees, and produce valuations that look precise, but are not even close to being estimates of true value.
Drown in data: If the complaint that analysts in the 1970s and even the 1980s might have had is that there was not enough data, the complaint today, when they value companies, is that there is too much data. That data is not only quantitative, with company disclosures running to hundreds of pages and databases that cover thousands of companies, but also qualitative, as you can access every news story about a company over its history, and in real time. Without guard rails, it is easy to see why this data overload can overwhelm investors and analysts, and lead them, ironically, to ignore most of it.
Denial of biases: It is almost impossible to value a business without bias, with some bias coming from what you know about the business and some coming from whether you are getting paid to do the valuation, and how much. In a valuation driven entirely with numbers, analysts can fool themselves into believing that since they work with numbers, they cannot be biased, when, in fact, bias permeates every step in the process, implicitly or explicitly. Put simply, there are very facts in valuation and lots of estimates, and if you are making those estimates, you are bringing your biases
If you are a number-cruncher, at heart, and have run into these or other problems when valuing companies, bringing numbers into your valuation can not just alleviate these problems, but also help you in convincing not just other people, but yourself, about your valuation.
Stories are memorable, numbers less so: Even the most-skilled number cruncher, aided and abetted with charts and diagrams, will have a difficult time creating a valuation that is even close to being as good a compelling business story, in hooking investors and being memorable. I believe that long after my students have forgotten what growth rates and margins I assumed in the valuation of Amazon that I showed them in 2012, they will remember my characterization of Amazon as my "field of dreams company", built on the premise that if they build it (revenues), they (profits) will come.
Stories allow for consistency-tests: When your valuation numbers come from a story, it becomes almost impossible to change one input to your valuation without thinking through how that change affects your story. An increase in revenue growth, in a company in a niche market with high margins, may require a recalibration of the story to make it a more mass-market story, albeit with lower margins.
Stories allow you to screen and manage data: Having a valuation story that binds your numbers together and yields a value also allows you a framework for separating the data that matters (information) from the data that does not (distractions), and for organizing that data.
Stories lead to business follow-through: If you are a business-owner, valuing your own business, understanding the story that you are telling in that valuation is extraordinarily useful in how you run the business. Thus, if you want to follow Amazon's path to the Field of Dreams, your business strategy should be built around expanding your market and increasing revenues, while also mapping out a pathway to eventually monetizing those markets and gaining access to enough capital to be able to do so.
If you are a number cruncher like me, you will find that adding a story to your valuation will only augment your number skills and improve your valuations.
2. Why numbers matter in a story world
I am not a story-telling natural, but I have tried to look at valuation, through the eyes of story tellers, over the last few years. Again, you start with some advantages, as a skilled story teller, especially if you also have the added benefit of charisma. You can use your story telling skills to draw investors, employees and the rest of the world into your story, and if you frame it well, you may very well be able to evade the type of scrutiny that comes with numbers. There are dangers, though, including the following:
Fairy tales: Without the constraint of business first principles or explicit numbers about key inputs, you can tell stories of unstoppable growth and incredible profits for your company that are alluring, but impossible. If you are a con man, that is your end game, but even if you are not a con man, it is easy to start believing your own tall stories about businesses. As you watch the unraveling of FTX, you have to wonder whether Sam Bankman-Fried (SBF) set out to create a crypto-based Ponzi scheme, or whether this is the end result of a business story that was unchecked by any of the big name investors who participated into its growth.
Anecdotal evidence: Story tellers tend to gravitate towards anecdotal data that supports their valuation stories. Rather than drown in the data overflow world we live in, story tellers pick and choose the data that best fits their stories, and use them to good effect, often fooling themselves about viability and profitability along the way.
Unconstrained biases: If number crunchers are in denial about their biases, story tellers often revel in their biases, presenting them as evidence of the conviction that they have in their stories. Using the FTX example again, SBF was open about his belief that the future belonged to crypto, and that his entire business was built on that belief, and to his audience, composed of other true crypto-believers, this was a plus, not a minus.
In every market boom, you see the rise of story tellers, and while many crash and burn like SBF, as reality bites, there are a few that succeed, building some of our greatest business successes. One reason is that they find a way to bring numbers into their stories, with the following benefits:
Numbers give credibility to stories: As we noted in the last section, stories are hooks that draw others to a business idea, but it may not be enough to get them to invest their money in it. For that to happen, you may have to use numbers to augment and back up your business story to give it credibility and create enough confidence that you have the business sense to make it succeed.
Numbers allow for plausibility checks: If you are on the other side of a valuation pitch, especially one built almost entirely around a story, the absence of numbers can make it difficult to take the story through the 3P test, where you evaluate whether it is possible, plausible and probable. It is your obligation as an investor to push for specificity, often in terms of the market that the business is targeting and the market share and profitability numbers that will determine its profitability. Again, business owners and analysts who can respond to this demand for specifics and numbers are more likely to get the capital that they seek.
Number create accountability: For business owners and managers, the use of numbers allows for accountability, where your actual numbers on total market size, market share and profitability can be compared to your forecasts. While that lead to uncomfortable findings, i.e., that you delivered below your expectations, it is an integral part of building a successful business over time, since what you learn from the feedback can allow you to alter, modify and sometimes replace business models that are not working well.
Just as great number crunchers can benefit from bring stories into their valuations, great story tellers will benefit by bringing in numbers to add discipline to their story telling.
The Facebook Narrative
In the last few months, as Facebook has collapsed, investors seem to have forgotten about its astonishing climb in the decade prior, with market capitalization increasing from $100 billion at its IPO in 2012 to its trillion-dollar capitalization in July 2021. In my view, a key factor behind the stratospheric rise was the valuation story told by and about the company, and the story's appeal to investors.
The Facebook Story
The core of the Facebook story is its mammoth user base, especially if you include Instagram and WhatsApp as part of the Facebook ecosystem, but if that is all you focused on, you would be missing large parts of its appeal. In fact, the Facebook story has the following constituent parts:
Billions of intense users: If there is one lesson that we should have learned from our experiences with user-based and subscriber-based companies over the last decade, it is that not all users or subscribers are created equal. With Facebook, it is not just the roughly three billion people who are in its ecosystem that should draw your attention, but the amount of time they spend in it. Until TikTok recently supplanted it at the top, Facebook had the most intense user base of any social media platform, with users staying on the platform roughly an hour a day in 2019.
Sharing personal data in their postings: As a platform that encourages users to share everything with their "friends", it is undeniable that Facebook has accumulated immense amounts of data about its users. If you are a privacy purist, and you find this unconscionable, it is worth noting that these users were not dragged on to a platform and forced to share their deeply personal thoughts and feelings, against their wishes.
Which could be utilized to focus advertising at them: In 2018, at the peak of the Cambridge Analytica scandals, when people were piling on Facebook for its invasion of privacy, I noted invading user privacy, albeit with their tacit approval, lies at the core of Facebook's success in online advertising. In short, Facebook uses what it has learnt about the people inhabiting its platform to focus advertising to them.
In a world where online ads were consuming the advertising business: Facebook also benefited from a macro shift in the advertising business, where advertisers were shifting from traditional advertising modes (newspapers, television, billboards etc.) to online advertising; online advertising increased from less than 10% of total advertising in 2005 to close to 60% of total adverting in 2020.
In sum, the story that took Facebook to the heights that it reached in July 2021 was that of an online advertising juggernaut, whose success came from using the data that it had acquired on the billions of users who spent a chunk of their days on on its platform, to deliver focused advertising.
And its appeal
Every business, especially in its youth, markets itself with a story and it is worth asking why investors took to Facebook's story so quickly and attached so much value to it.
Simple and easy to understand: In telling business stories, I argue that it pays to keep the story simple and to give it focus, i.e., lay out the pathways that the story will lead the company to make money. Facebook clearly followed this practice, with a story that was simple and easy for in investors to understand and to price in. Just to provide a contrast, consider how much more difficult it is for Palantir or Snowflake to tell a business story that investors can grasp, let alone value.
Personal experiences with business: Adding to the first point, investors feel more comfortable valuing businesses, where they have sampled the products or services offered by these businesses and understand what sets them apart (or does not) from the competition. I would wager that almost every investor, professional or retail, who invested in Facebook has a Facebook page, and even if they do not post much on the page, have seen ads directed specifically at them on that page.
Backed up by data: In the last decade, we have seen other companies with simple stories that we have personal connections to, like Uber, Airbnb and Twitter, go public, but none of them received the rapturous response that Facebook did, at least until July 2021. The reason is simple. Unlike those companies, Facebook, from day one as a public company, has been able to back its story up with numbers, both in terms of revenues and profitability, as can be seen in the graph below, where I look at its revenues and operating profits from 2012 to 2021:
With revenues growing from less than $4 billion in 2011 to $118 billion in 2021, and operating margins of more than 40%,through almost the entire period, it is easy to see why both value and growth investors gravitated to this stock.
With value consequences
I have valued Facebook many times over the last decade, and have bought and sold based upon my valuations. For those of you who have been following these valuations, I am sure that you are well aware that my most recent valuation of Facebook, at the end of February 2022, was $346 per share, well above the stock price then of $220/share:
Having bought shares in the company at $133/share after the Cambridge Analytica scandal in 2018, I stayed invested in the company. Obviously, at today's price of just over $100/share, it should be time for regrets, but I have none. There are clearly aspects of my valuation, where I overreached, including revenue growth of 8% a year that I would reset to a lower number, with the recognition that online advertising is seeing growth level off, faster than I thought it would, and is more cyclical than I assumed it would be. As for profitability, my estimated target operating margin of 40% looks hopelessly optimistic, given that the operating margins in the last twelve months is closer to 20%, but as I noted in my last post, that drop is less a reflection of a collapse in the online advertising business model and more the result of Facebook's big bet of Metaverse, and the expenses emanating from that bet.
Narrative Changes and Resets
The value of a business is, in large part, driven by your story for the business, but that story will change over time, as the business, the market it is in and the macro environment change. In some cases, the story can get bigger, leading to higher value, and in some, it can get smaller, and we will begin by looking at why business stories change, and classify those changes, before looking at the Facebook story.
Narrative Breaks, Changes and Shifts
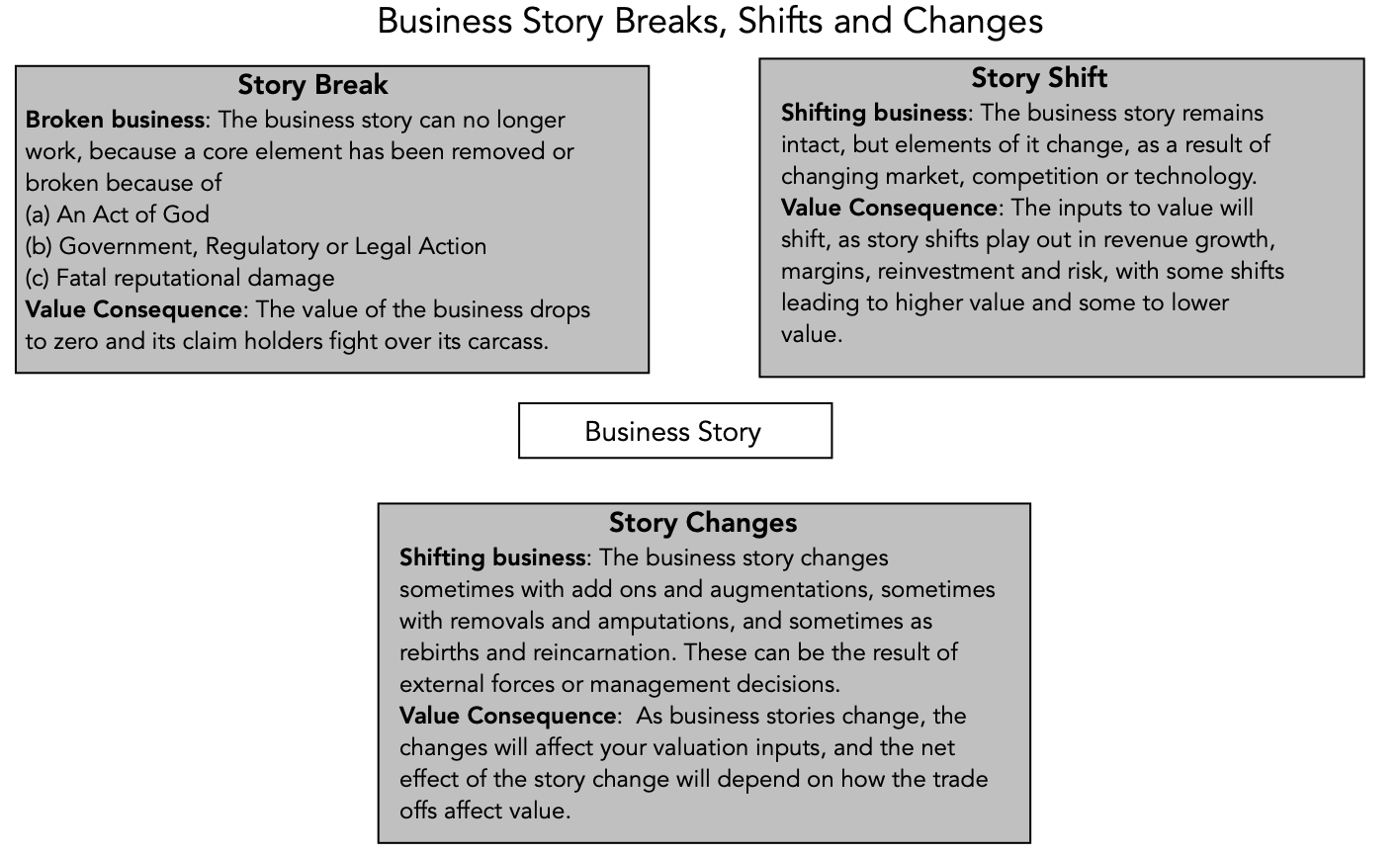
If business stores change over time, what form will that change take? To answer the question, I broke down business story changes into three groups, with the proviso that there are some business changes that fall into more than one group:
Story breaks: The most consequential value change comes from a story break, where a key component of a business story breaks, sometimes due to external factors and sometimes due to miscalculations and missteps on the part of the management of the company. In the former group, we would include acts of God (terrorism, a hurricane or COVID) and regulatory or legal events (failure to get regulatory approval for a drug, for a pharmaceutical company) that put an end to a business model. In the latter, we would count companies where management pushed the limits of the law to breaking point and beyond, damaging its reputation to the point that it cannot continue in business.
Story shifts: At the other end of the spectrum are story shifts, where the core business model remains intact, but its contours (in terms of growth, profitability and risk) change, as the result of market changes (market growth surges, slows or stalls), competitive dynamics (a competitor introduces a new product or withdraws an existing one) or technology (working in favor of the story or against it). Note the resulting changes in value can be substantial, and in either direction, depending on how and how much the valuation inputs change as a result of the story shift.
Story changes: Finally, there are story changes, where a company augments an existing business story by investing in or acquiring a new business, shrinks its existing business by withdrawing or divesting an existing business or product or attempts a story reset or rebirth, by replacing an existing business story with a new one.
I summarize these possible story alterations in the picture below:
As you can see from the types of changes that can occur, some business story changes are triggered by external forces, and can be traced to changes in macroeconomic conditions, country risk or regulatory/legal structures, some business story changes are the result of management actions, at the company or at its competitors and some business story changes are the consequence of a company scaling up and/or aging. It is worth noting that disruption, at its core, creates changes to a sector or industry that can break some status-quo businesses, while creating new ones with significant value.
Facebook: A Narrative Reset?
In the last section, we looked at the incredible success that Facebook had between 2012 and 2021 with its user-driven, online advertising business model, both in terms of market capitalization (rising from $100 billion to $ 1 trillion) and in terms of operating results. You may wonder why a company that has had this much success with its story would need to change, but the last year and a half is an indication of how quickly business conditions can change.
Forces driving a reset
Facebook's original business story was built on two premises, with the first being the use of data that it obtained on its customers to deliver more focused advertisements and the second being the rapid growth in the online advertising business, largely at the expense of traditional advertising. Both premises are being challenged by developments on the ground, and as they weaken, so is the pull of the Facebook story.
On the privacy front, the Cambridge Analytica episode, though small in its direct impact, cast light on an unpleasant truth about the Facebook business model, where the invasion of user privacy is a feature of its business story, not a bug. Put differently, if Facebook decides not to use the information that you provide it, in the course of your postings, in its business model, a large portion of its allure to advertisers disappears.
The halcyon days of growth in the online advertising market are behind us, as it acquires a dominant share of overall advertising, and starts growing at rates that reflect growth in total advertising. As one of the two biggest players in the market, with Google being the other one, Facebook does not have much room on the upside for growth.
While many investors were shocked by the stagnant revenues that Facebook reported in its most earnings report, and some have attributed that to a slowing economy, the truth is that the pressures on Facebook's business story have been building for a while, and it is only the speed with which the story has unraveled that is shocking.
Choices for the company
Faced with slower revenue growth and concerned about the effect that privacy regulations in the EU and the US will alter its business model, Facebook has been struggling with a way forward. As I see it, there were three choices that Facebook could have made (though we know, in hindsight, which one they picked):
Acceptance: Accept the reality that they are now a mature player in a slow-growth business (online advertising), albeit one in which they are immensely profitable, and scale back growth plans and spending. While this may strike some as giving up, it does provide a pathway for Facebook to become a cash cow, investing just enough in R&D to keep its existing business going for the foreseeable future, while returning huge amounts of cash to its investors each year (as dividends or buybacks).
Denial: View the slowdown in growth in the online adverting market as temporary, and stay with its existing business model, built around aggressively seeking to gain market share from both traditional players in the advertising market and smaller online competitors. With this path, the company may be able to post higher revenue growth than if it follows the acceptance path, but perhaps with lower operating margins and more spending on R&D, if market growth is leveling off.
Rebirth: The choice with the most upside as well as the greatest downside is for Facebook to try to reinvent itself in a new business. That may require substantial reinvestment to enter the business, and hopefully draw on Facebook’s biggest strength, i.e., its intense and mammoth user base.
Facebook did pick the third path, and it made the choice well before the revenue slowdown in the most recent year, perhaps as early as 2014, with its acquisition of Oculus for $2 billion. In the last three years, the push into the Metaverse has intensified, with billions invested in Reality Labs and a name change for the company.
Facebook has also telegraphed its commitment to be a leading player in this space, planning to invest close to $100 billion, over the next decade. The big question, as I noted in my last post, that hangs over the company is whether this investment can create enough in additional earnings and cash flows to cover these huge upfront costs.
What's the story?
Facebook’s plans to invest tens of billions in the Metaverse makes it an expensive venture, by any standards, and there are some who suggest that it is unprecedented, especially in technology, which many view as a capital-light business. That perception, though, collides with reality, especially when you look at how much big tech companies have been willing to invest to enter new businesses, albeit with mixed results.
Microsoft invested $15 billion for its entry in 2015 into Azure, its cloud business, and it has invested tens of billions in data centers since, expanding its reach. That investment has paid off both quickly and lucratively, and has played a role in Microsoft's rise in market capitalization.
Google, renamed itself Alphabet in 2015, in a well-publicized effort to rebrand itself as more than just a search engine, and has invested tens of billions of dollars in its other businesses since, but with a payoff primarily in its cloud business, which generated $19.2 billion in revenues in 2021. Just to provide a measure of how its other bets are still lagging, Google generated only $753 million in revenues from its other businesses in 2021, almost unchanged from its revenues in 2019 and 2020.
Amazon has also invested tens of billions in its other businesses, with its biggest payoff coming in the cloud business (notice a pattern here). It has much less to show for its investments in Alexa and entertainment, and it is estimated to have lost $5 billion on its Alexa division in 2021 and spent $13 billion on new content for Amazon video.
Facebook, Microsoft and Google have all used the cash flows from their core businesses (Online advertising for Facebook and Google, Windows and Office for Microsoft) to fund their entry into new businesses, but at Amazon, it is the AWS (its cloud business) that has provided the profits and cash flows to cover its growth plans in other businesses.
Facebook's investment plans for the Metaverse represent a big bet, but it is not an unprecedented one, which raises the question of why investors have been less willing to cut it slack than they have for its large tech competitors. One reason is timing, since markets are much more receptive to big growth investments, when times are good, as they were for much of the last decade, than in bad times, as much of 2022 has been. The other is the story line that backs the investment. Fairly or otherwise, the big cloud investments that Microsoft, Google and Amazon made came with story lines of growth and profitability that investors bought into, and for the most part, the results have justified that view. The more opaque investments, including Google's bets and Amazon's Alexa and prime video spending have been viewed more skeptically. The problem that most investors have with Facebook's Metaverse investment is that it is not just that the payoff is uncertain, but it is unclear what business the payoff will come from. After all, the Metaverse is a space (virtual), not a business, and to make money in that space, you need a business model, which Facebook has not provided much guidance on. In fact, the most detailed document that I was able to find anything on Facebook's Metaverse plans were from 2015, where Zuckerberg described his vision for the business, and from 2018, in a 50-page presentation that Facebook, where the company talks about revenues coming from advertising and hardware, but only in very general terms. It is true that Facebook has laid out its Connect 2021 vision online, but the document is heavy on hype and technology, and light on business details.
As I see it, the combination of market conditions and opacity about business plans is creating the worst of all combinations for Facebook, in financial markets. The market has clarity about how much Facebook plans to spend on the Metaverse and is not just skeptical, but extremely confused, about how exactly Facebook will make money in the Metaverse. To give you a sense of how negative investors are about Facebook's future prospects, I created the most conservative estimate of value, which I call my Doomsday valuation, for the company based upon the following assumptions:
I used the company's actual operating income from its online advertising business from the last twelve months, weighed down as they are from a slowing economy and a stronger economy, and assumed no growth and a remaining life of 20 years for the business, with a zero liquidation value at the end of year 20.
I assumed that the company will continue to spend R&D at the same scorching rate that it set in the last twelve months, where it spent just over $32 billion on R&D, for the next 20 years.
I also assumed that not only will Facebook to lose $10 billion a year on the Metaverse, but also that this will continue for the next decade and beyond, with no payoff in terms of increased revenues or earnings from this spending.
I assume that Facebook is a risky company, falling at the 75th percentile of all US companies in terms of risk, and give it a cost of capital of 9%.
The table below shows the value that I estimate with this combination of assumptions, and compares it to the value that I would obtain, if I removed the Metaverse numbers from the valuation:
Note that in Doomsday scenario, where Facebook continues to spend money on R&D and invest heavily in the Metaverse, with no payoff in higher growth or longer business life from those investments, the value of equity that I obtain is $258.6 billion. Doing the valuation with the Metaverse revenues and expenses removed from the mix yields $330 billion, suggesting that treating the entire Metaverse investment as wasted expenditure reduces Facebook's value by approximately $71 billion.
The market capitalization of Facebook on October 29, 2022 was $247 billion, below the Doomsday scenario value, indicating that investors were, in fact, treating the $100 billion to be invested in the Metaverse as a wasted expense, a remarkably cynical and pessimistic take on a company that has had a history of delivering profits. The market capitalization has risen to $311 billion as of November 15, 2022, and while that suggests a more positive perspective, that value still reflects a presumption that the Metaverse investment will destroy about $18.9 billion of Facebook's value. In truth, using a more realistic growth rate (rather than zero) or lowering the cost of capital (from 9% to 8%, the median cost of capital for a US company) or extending the life of the company (from 20 years to a longer period) can only add value to Facebook, and you can experiment with these inputs in the attached spreadsheet.
Turning the Trust Corner
It is undeniable that Facebook has lost the trust of investors, and that it is being priced on assumptions that reflect that mistrust. In my experience, trying to jawbone investors to trust you does not work, but there is a plan of action that Facebook can follow, that will start the process of rebuilding trust :
Tell with a business story for the Metaverse: Investors do not have a clear sense of what the Metaverse is, and more importantly, the business opportunities that exist in that space. Facebook needs to fill in that gap with a business story for its investments, laying out what is sees as a pathway to making money in that virtual world, as well as the strengths it will bring to delivering value on this path. I am sure that Facebook is much more qualified than I am to frame this story, but just in case they could use some guidance, here are a few possible Metaverse business models:
Of these choices, advertising clearly is the most logical extension of their existing business, but it also offers the least upside, since the company is already a dominant player in the online ad business. The acquisition of Oculus and the VR headsets that Facebook sells give it a foothold in the hardware business, but hardware is a business with lower margins and limited market size. The most lucrative story, in my view, is a ecosystem story, where Facebook gains a dominant share of the virtual world, and takes a slice of any business (transactions, gaming, subscriptions) done in that world, mirroring what Apple has done in its iPhone ecosystem. It is worth remembering that the audience that you are trying to sell this business story to is not the audience that you will be seeking out in the Metaverse, which would imply that your story should be less about technology and more about business. (I may be old and cranky. I have zero interest in the virtual world, but as a Facebook investor, I would be interested to learn its business model for this world.)
Build in specifics into your investment story: Facebook has been clear about its plans to invest billions in its new businesses, but rather than just emphasizing the total amount that it plans to make, it would be better served connecting its investment plans with the business story being told. If nothing else, it would be useful to know how much of the $12 billion spent in Reality Labs was spent on people, on technology, on software and in making better VR glasses and why all of this spending is bringing the company closer to a money-making business model.
With markers on operating payoffs: I know that there are huge uncertainties overhanging these investments, but it would still make sense to give rough estimates of how Facebook expects revenues and operating margins to evolve on its Metaverse investment, over time. That will give investors and managers targets to track, as the company delivers results, and use the results (positive or negative) to make changes in the way future investments are made.
And escape hatches, if things don't work out: While many companies refuse to talk about what their plans are, if a business does not pan out, viewing it as a sign of weakness or lack of conviction, I believe that Facebook will be best served if they are open about what can go wrong with their Metaverse bet, and not only about what they are doing to protect themselves, if it happens, but also exit plans, if they decide to walk away. After all, if the market is already assuming the worst, as it was just a couple of weeks ago, how can any scenario you present, no matter how negative, worsen your market standing?
As I mentioned in my first post on Facebook a couple of weeks ago, I made an exception to my rule of not doubling down and doubled my holding of Facebook on November 4, 2022, because its valuation looks compelling. I did so with the acceptance that I will have little influence over the management of the company, in general, and Mark Zuckerberg, in particular, and it is entirely possible that I will come to regret it. If I do so, I am sure that many of you will remind me, and I okay with that as well!