My not-so-profound thoughts about valuation, corporate finance and the news of the day!
Saturday, January 8, 2022
Data Update 1 for 2022: It is Moneyball Time!
Happy New Year, and I hope that 2022 brings you good tidings! To start the year, I returned to a ritual that I have practiced for thirty years, and that is to take a look at not just market changes over the last year, but also to get measures of the financial standing and practices of companies around the world. Those measures took a beating in 2020, as COVID decimated the earnings of companies in many sectors and regions of the world, and while 2021 was a return to some degree of normalcy, there is still damage that has to be worked through. This post will be one of a series, where I will put different aspects of financial data under the microscope, to get a sense of how companies are adapting (or not) to a changing world.
The Moneyball Question
When I first started posting data on my website for public consumption, it was designed to encourage corporate financial analysts and investors alike to use more data in their decision making. In making that pitch, I drew on one of my favorite movies, Moneyball, which told the story of Billy Beane (played by Brad Pitt), the general manager of the Oakland As, revolutionized baseball by using data as an antidote to the gut feeling and intuition of old-time baseball scouts.
In the years since Beane tried it with baseball, Moneyball has decisively won the battle for sporting executives' minds, as sport after sport has adopted its adage of trusting the data, with basketball, football, soccer and even cricket adopting sabermetrics, as this sporting spin off on data science is called. Not surprisingly, Moneyball has found its way into business and investing as well. In the last decade, as tech companies have expanded their reach into our personal lives, collecting information on choices and decisions that used to private, big data has become not just a buzzword, but also a justification for investing billions in companies/projects that have no discernible pathway to profitability, but offer access to data. Along the way, we have all also bought into the notion of crowd wisdom, where aggregating the choices of tens of thousands of choice-makers, no matter how naive, yields a consensus that beats expert opinion. After all, we get our restaurant choices from Yelp reviews, our movie recommendations from Rotten Tomatoes, and we have even built crypto currencies around the notion of crowd-checking transactions.
Don't get me wrong! I was a believer in big data and crowd wisdom, well before those terms were even invented. After all, I have lived much of my professional life in financial markets, where we have always had access to lots of data and market prices are set by crowds of investors. That said, it is my experience with markets that has also made me skeptical about the over selling of both notions, since we have an entire branch of finance (behavioral finance/economics) that has developed to explain how more data does not always lead to better decisions and why crowds can often be collectively wrong. As you use my data, I would suggest four caveats to keep in mind, if you find yourself trusting the data too much:
More data is not always better than less data: In a post from a few months ago, I argued that we as investors and analysts) were drowning in data, and that data overload is now a more more imminent danger than not have enough data. I argued that disclosure requirements needed to be refined and that a key skill that analysts will need for the future is the capacity to differentiate between data and information, and materiality from distraction.
Data does not always provide direction: As you work with data, you discover that its messages are almost always muddled, and that estimates always come with ranges and standard errors. In short, the key discipline that you need to tame and use data is statistics, and it is one reason that I created my own quirky version of a statistics class on my website.
Mean Reversion works, until it does not: Much of investing over the last century in the US has been built on betting on mean reversion, i.e. that things revert back to historical norms, sooner rather than later. After all, the key driver of investment success from investing in low PE ratio stocks comes from their reverting back towards the average PE, and the biggest driver of the Shiller PE as a market timing device is the idea that there is a normal range for PE ratios. While mean reversion is a strong force in stable markets, as the US was for much of the last century, it breaks down when there are structural changes in markets and economies, as I argued in this post.
The consensus can be wrong: A few months ago, I made the mistake of watching Moneyheist, a show on Netflix, based upon its high audience ratings on Rotten Tomatoes, and as I wasted hours on this abysmal show, I got a reminder that crowds can be wrong, and sometimes woefully so. As you look at the industry averages I report on corporate finance statistics, from debt ratios to dividend yields, remember that just because every company in a sector borrows a lot, it does not mean that high debt ratios make sense, and if you are using my industry averages on pricing multiples, the fact that investors are paying high multiples of revenues for cloud companies does not imply that the high pricing is justified.
In short, and at the risk of stating the obvious, having access to data is a benefit but it is not a panacea to every problem. Sometimes, less is more!
The Company Sample for 2022
When I first started my data collection and analysis in 1990, data was difficult to come by, and when available, it was expensive. Without hundreds of thousands of dollars to spend on databases, I started my journey spending about a thousand dollars a year, already hitting budget constraints, subscribing to a Value Line database that was mailed to me on a CD every year. That database covered just 1700 US companies, and reported on a limited list of variables on each, which I sliced and diced to report on about a dozen variables, broken down by industry. Times have changed, and I now have access to extraordinarily detailed data on almost all publicly traded global companies. I am grateful to all the services that provide me with raw data, but I am cognizant that they are businesses that make money from selling data, and I try not to undercut them, or act as a competitor. That is why almost every variable that you will see me reporting on my website represents a computation or estimate of mine, albeit with raw data from a provider, rather than a regurgitation of data from a service. It is also why I report only aggregated data on industries, rather than company-level data.
Regional Breakdown
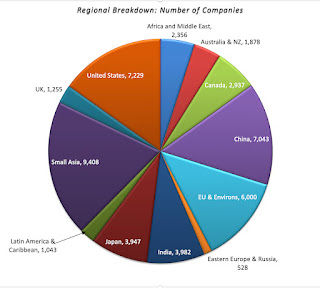
My data sample for 2022 includes every publicly traded firm that is traded anywhere in the world, with a market capitalization that exceeds zero. That broad sweep yields a total of 47,606 firms, spread across 135 countries and every continent in the world:
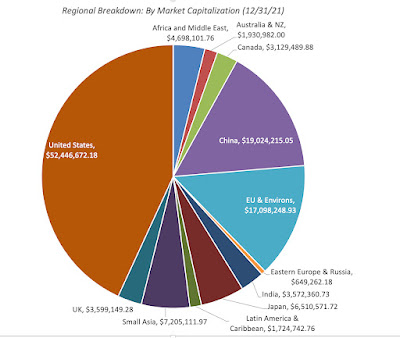
The largest slice is Small Asia, where small has to be read in relative terms, since it includes all of Asia, except for India, China and Japan, with 9,408 firms. It is followed by the United States, with 7,229 firms, and then China (including Hong Kong listings), with 7.043 firms. Since many of these firms have small market capitalizations, with some trading at market caps of well below $10 million, the chart below looks at the breakdown of the sample in market capitalization:
The market capitalization breakdown changes the calculus, with the US dominating with $52 trillion in collective market cap, more than 40% of the overall global value, followed by China with $19 trillion in aggregate market capitalization.
Sector/Industry Breakdown
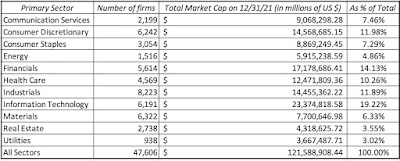
The most useful way to categorize these 47,606 companies is by industry groupings, but that process does raise thorny questions about what industry groupings to use, and where to put firms that are not easily classifiable. To illustrate, what business would you put Apple, a company that was categorized (rightly) as a computer hardware company 40 years ago, but that now gets more than 60% of its revenues and profits from the iPhone, a telecommunication device that is also a hub for entertainment and services? I started my classification with a very broad grouping, based upon S&P's sector classes:
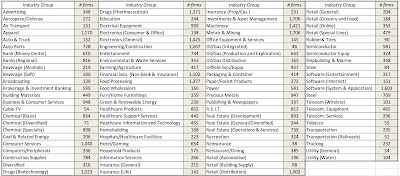
This should not come as a surprise, especially given their success in markets over the last decade, but technology is the largest sector, accounting for 19.22% of global market capitalization, though industrials account for the largest number of publicly traded firms. One sector to note is energy, which at 4.86% of global market capitalization at the start of 2022, has seen its share of the market drop by roughly half over the last decade. Addressing the legitimate critique that sector classifications are too broad, I created 94 industry groupings for the companies, drawing on the original classifications that I used for my Value Line data thirty years ago (to allow for historical comparisons) and S&P's industry list. The table below lists my industry groups, with the number of companies in each one:
I am sure that some of you will find even these industry groupings to be over-broad, but I had to make a compromise between having too many groupings, with not enough firms in each one, and too few. It also required that I make judgment calls on where to put individual firms, and some of those calls are debatable, but I feel comfortable that my final groups are representative.
The Data Variables
When I first started reporting data, I had only a dozen variables in my datasets. Over time, that list has grown, and now includes more than a hundred variables. A few of these variables are macro variables, but only those that I find useful in corporate finance and valuation, and not easily accessible in public data bases. Most of the variables that I report are micro variables, relating to company choices on investing, financing and dividend policies, or to data that may be needed to value these companies.
Macro Data
If your end game is obtaining macroeconomic data, there are plenty of free databases that provide this information today. My favorite is the one maintained by the Federal Reserve in St. Louis, FRED, which contains historical data on almost every macroeconomic variable, at least for the US. Rather than replicate that data, my macroeconomic datasets relate to four key variables that I use in corporate finance and valuation.
Risk Premiums: You cannot make informed financial decisions, without having measures of the price of risk in markets, and I report my estimates for these values for both debt and equity markets. For debt markets, it takes the form of default spreads, and I report the latest estimates of these corporate bond spreads at this link. In the equity market, the price of risk (equity risk premium) is more difficult to observe, and I start by reporting on the conventional estimate of this measure by looking at historical returns (going back to 1928) on stocks, bonds, bills and real estate at this link. I offer an alternative forward-looking and more dynamic measure of this premium in an implied premium, with the start of 2022 estimate here and the historical values (going back to 1960) of this implied premium here.
Risk free Rates: While the US treasury bond rate is widely reported, I contrast its actual value with what I call an intrinsic measure of the rate, computed by adding the inflation rate to real growth each year at this link.
Currency and Country Risk: Since valuation often requires comfort with moving across currencies, I provide estimates of risk free rates in different currencies at this link. I extend my equity risk premium approach to cover other countries, using sovereign default spreads as my starting point, at this link.
Tax Rates: Since the old saying about death and taxes is true, I report on marginal tax rates in different countries at this link, and while I would love to claim that I did the hard work, the credit belongs to KPMG for keeping this data updated over time.
I do update my equity risk premiums for the US at the start of every month on my website, and the country equity risk premiums once every six months.
Micro Data
I am not interested in reported financial ratios, just for the sake of reporting them, and my focus is therefore on those statistics that I use in corporate finance and valuation. You may find my choices to be off putting, but you could combine my reported data to create your own. For example, I believe that return on assets, an accounting ratio obtained by dividing net income by total assets, is an inconsistent abomination, leading to absurd conclusions, and I refuse to report it, but I do report returns on invested capital and equity.
Rather than just list out the variables that I provide data on, I have classified them into groups in the table below:
With each of these variables, I report industry averages for all companies globally, as well as regional averages for five groups: (a) US, (b) EU, UK and Switzerland, (c) Emerging Markets, (d) Japan and (e) Australia, NZ and Canada. Since the emerging market grouping is so large (representing more than half my sample) and diverse (across every continent), I break out India and China as separate sub-groups. You can find the data to download on my website, at this link.
Data Timing and Timeliness
Almost all of the data that you will see in my updates reflects data that I have collected in the last week (January 1, 2022- January 8, 2022. That said, there will be difference in timeliness on different data variables, largely based upon whether the data comes from the market or from financial statements.
For data that comes from the market, such as market capitalization and costs of capital, the current data is as of January 1, 2022.
For data that comes from financial statements, the numbers that I use come from the most recent filings, which for most companies will be data through September 30, 2021.
Thus, my trailing PE ratio for January 1, 2022, is computed by dividing the market capitalization on January 1, 2022, by the earnings in the twelve months ending in September 2021. While that may seem inconsistent, it is consistent with the reality that you, as an investor or analyst, use the most current data that you can get for each variable. As we go through the year, both the market and the accounting numbers will change, and a full-fledged data service would recompute and update the numbers. I am not, and have no desire to be, a data service, and will not be updating until the start of 2023. Thus, there are two potential dangers in using my data later in the year, with the first emerging if the market sees a steep shift, up or down, which will alter all of the pricing multiples, and the second occurring in sectors that are either transforming quickly (disrupted sectors) or are commodity-based (where changes in commodity prices can alter financials quickly).
Estimation Choices
When I embarked on the task of estimating industry averages, I must confess that I did not think much of the mechanics of how to compute those averages, assuming that all I would have to do is take the mean of a series of numbers. I realized very quickly that computing industry averages for pricing and accounting ratios was not that simple. To illustrate why, I present you with a slice of my table of PE ratios, by industry grouping, for US firms, the start of 2022:
Take the broadcasting group, just as an illustration, where there were 29 firms in my US sample. The three columns with PE ratios (current, trailing and forward) represent simple averages, but these case be skewed for two reasons. The first is the presence of outliers, since PE ratios can be absurdly high numbers (as is the case with auto & truck companies), and can pull the averages up. The second is the bias created by removing firms with negative earnings, and thus no meaningful PE ratio, from the sample. The last two columns represent my attempts to get around these problems. In the second to last column, I compute an aggregated PE ratio, by taking the total market capitalization of all firms in the group and dividing by the total earnings of all firms in the group, including money losers. In effect, this computes a number that is close to a weighted average that includes all firms in the group, but if a lot of firms are money-losers, this estimate of the PE ratio will be high. To see that effect, I compute an aggregated PE ratio, using only money-making firms, in the last column. You may look at the range of values for PE ratios, from 7.05 to 24.99 for broadcasting firms, and decide that I am trying to confuse the issue, but I am not. It is the basis for why I take all arguments that are based upon average PE ratios with a grain of salt, since the average that an analyst uses will reflect the biases they bring to their sales pitches.
The other issue that I had to confront, especially because my large sample includes many small companies, listed and traded in markets with information disclosure holes, is whether to restrict my sample to markets like the US and Europe, where information is more dependable and complete, or to stay with my larger sample. The problem with doing the former is that you create bias in your statistics by removing smaller and risker firms from your sample, and I chose to have my cake and eat it too, by keeping all publicly traded firms in my global sample, but also reporting the averages for US and European firms separately.
Using the Data
I report the data on my website, because I want it to be used. So, if you decide that some of the data is useful to you, in your investing or analysis, you are welcome to use it, and you don't have to ask for permission. If you find errors in the data, please let me know, and I will fix it. If you are looking for a variable that I do not compute, or need an average for a region that I don't report separately on (say Brazil or Indonesia), please understand that I cannot meet customized data requests. I am a solo operator, with other fish to fry, and there is no team at my disposal. As I mention in my website, this data is meant for real time analysis for those in corporate finance and valuation. It is not designed to be a research database, though I do have archived data on most of the variables going back in time, and you may be able to create a database of your own. If you do use the data, I would ask only three things of you:
Understand the data: I have tried my best to describe how I compute my numbers in the spreadsheets that contain the data, in worksheets titled "Variables and FAQ". On some of the variables, especially on equity risk premiums, you may want to read the papers that I have, where I explain my reasoning, or watch my classes on them. Whatever you do, and this is general advice, never use data from an external source (including mine), if you do not understand how the data is computed.
Take ownership: If you decide to use any of my data, especially in corporate financial analysis and valuation, please recognize that it is still your analysis or valuation.
Don't bring me into your disagreements, especially in legal settings: If you are in disagreement with a colleague, a client or an adversary, I am okay with you using data from my website to buttress your arguments, but please do not bring me in personally into your disputes. This applies in spades, if you are in a legal setting, since I believe that courts are where valuation first principles go to die.
Conclusion
I would love to tell you that I am driven by altruistic motives in sharing my data, and push for sainthood, but I am not. I would have produced all of the data that you see anyway, because I will need it for my work, both in teaching and in practice, all year. Having produced the data, it seems churlish to not share it, especially since it costs me absolutely nothing to do so. If there is a hidden agenda here, it is that I think that in spite of advances over the last few decades, the investing world still has imbalances, especially on data access, and I would like it make a little flatter. Thus, if you find the data useful, I am glad, and rather than thank me, please pass on the sharing.
Dear Professor, it seems that not all link are working properly - e.g. "Macro Data" paragraph, 1. Risk Premiums. Then if you try to open the link for the "implied premium" it does not open.
Thanks a lot for the data and the effort you are putting in!


1 comment:
Dear Professor, it seems that not all link are working properly - e.g. "Macro Data" paragraph, 1. Risk Premiums. Then if you try to open the link for the "implied premium" it does not open.
Thanks a lot for the data and the effort you are putting in!
Best
Post a Comment